Обращение по инциденту при замене дисков
Здравствуйте.
Направляю данное обращение для рассмотрения профильными специалистами, в чьей компетенции находится разбор инцидентов, связанных с ненадлежащим исполнением обязательств перед клиентами.
При рассмотрении прошу учитывать не выборочно, а полностью весь контекст коммуникации в тикете 3918824. Ниже привожу хронологию с указанием конкретных временных меток и цитат из переписки.
19.03.2026 на сервере Joule один из двух NVMe-дисков выпал из RAID-1 массивов. Сервер продолжил штатную работу на оставшемся диске. 30.03.2026 было подано обращение на замену неисправного диска.
В результате действий инженеров Selectel был извлечен рабочий диск с актуальными данными. Это привело к потере дисковых данных за период 19.03–30.03.2026 и длительному процессу восстановления консистентности баз данных.
Ввиду специфики проекта (платформа для психологов и их клиентов), инцидент привёл к утрате данных части психологов, клиентов, расконсистенции терапевтических сессий, нарушению платёжной логики и, что наиболее критично, к цепной утрате доверия в связке «клиент — психолог — платформа». В области, где доверие является профессиональным фундаментом, подобная цепная реакция наносит ущерб, несопоставимый со стоимостью дискового пространства.
Клиент открывает тикет:
Приложен вывод mdstat и скриншот. Серийный номер не указан.
Поддержка предлагает диагностику в Rescue. Серийный номер диска не запрошен. О нём не идёт даже речи. В случае обнаружения неисправного диска — замена поддержкой предлагается «сразу», без идентификации диска клиентом по S/N.
Поддержка сообщает результаты диагностики из Rescue-среды Selectel:
Маппинг имя→серийник предоставлен из Rescue-среды без какой-либо оговорки о том, что имена устройств могут различаться между средами загрузки. В том же сообщении предоставлен план действий по замене дисков, не предполагающий идентификации по S/N:
Клиент, полагаясь на предоставленный поддержкой маппинг и прямую пошаговую инструкцию от поддержки со ссылкой на базу знаний Selectel, сообщает:
и подтверждает замену:
Поддержка сообщает:
Клиент:
Поддержка предоставляет KVM «в качестве исключения, бесплатно (временно)».
SSH по-прежнему connection refused (порт 2245). KVM показывает No Signal. Клиент запрашивает перезагрузку сервера.
Через KVM обнаружено: сервер в emergency mode из-за отсутствующего EFI-раздела. После ручного исправления fstab — обнаружена потеря данных. Последняя запись в БД: 2026-03-19 12:26:11.
Поддержка:
и
Поддержка:
Ответ получен в 13:15.
Поддержке Selectel было известно:
- Собственная Rescue-среда (Arch Linux) и её особенности
- Среда клиента (Debian)
- Что имена устройств могут различаться между средами загрузки (подтверждено самой поддержкой позднее 31.03, 13:15: «используемая нами Rescue-система на базе Arch Linux может иметь иные идентификаторы устройств»)
- Что массив деградирован и диски рассинхронизированы
- Серийные номера обоих дисков
Клиенту было известно:
- Своя среда (Debian)
- Имя диска в своей среде (nvme1n1)
- Что массив деградирован
- План действий по замене дисков от поддержки обещающий замену «без потери данных», не предполагающий идентификацию по S/N
- Серийные номера НЕ были проверены (клиент положился на маппинг от специалистов)
Клиент не мог знать:
- Что в данной конкретной конфигурации имена устройств фактически поменялись местами
- Что предоставленный поддержкой маппинг имя→S/N не соответствует именам устройств в ОС клиента
Это классическая асимметрия информации. Сторона с полной картиной (Selectel) обязана была предупредить о расхождении или запросить однозначный идентификатор (серийный номер) до того, как предоставлять маппинг из своей среды. Вместо этого поддержка самостоятельно предоставила программный маппинг из Rescue-среды без оговорок, представив его как достоверную информацию для принятия клиентом решения о замене.
Клиент, не зная об особенностях чужой Rescue-среды, воспринял этот маппинг как корректный и подтвердил замену по имени из среды диагностики поддержки Selectel.
Помимо предоставления маппинга без предупреждения, поддержка прямо заявила, пообещав замену без потерь — «мы можем выполнить замену без потери данных... Для этого вам необходимо...» (31.03, 00:17), предоставила план действий по замене дисков, где сослалась на статью из базы знаний Selectel с пошаговой инструкцией по администрированию RAID при замене дисков (https://docs.selectel.ru/dedicated/troubleshooting/replace-disk-raid/). Характерно, что и в самой этой статье идентификация дисков выполняется исключительно по именам устройств (sda, sdb) — серийный номер или команды, определяющие его, не упоминаются ни разу. Таким образом, собственная документация Selectel не содержит процедуры верификации по S/N, отсутствие которой позднее было предъявлено клиенту как причина инцидента. Данные были потеряны.
В сообщении от 31.03, 13:15 Selectel сам пришёл к выводу:
В том же сообщении признано:
И в том же сообщении заявлено:
Это же сообщение от 31.03, 13:15 содержит предложение вернуть заменённый диск для восстановления данных. Однако ответ «на ключевые» вопросы, обещанный «приблизительно до 10:00» (31.03, 02:55), поступил в 13:15 — спустя более 3 часов после обещанного срока. К этому моменту проект уже функционировал в частично рабочем режиме (для части пользователей), накапливая новые данные и транзакции, всё ещё велись работы по восстановлению утраченной консистентности. Возврат диска и откат к его содержимому привёл бы к потере новых данных и повторной расконсистенции.
Важно отметить: маппинг имя→серийник — это программная идентификация, выполненная в Rescue-среде. Selectel дважды заявлял, что «не выполняет администрирование серверов». Однако предоставление программного маппинга дисков — это прямое взаимодействие с программной частью сервера, а предоставление плана действий по работе с RAID с обещанием «без потери данных» — прямое руководство по программному администрированию. Причём именно маппинг из чужой среды, транслированный клиенту как достоверный, привёл к инциденту.
Примечательно, что в первом же ответе поддержки (31.03, 00:01) было заявлено:
Замена планировалась сразу — без запроса серийного номера у клиента, без подтверждения S/N конкретного диска, автоматически по результатам диагностики в Rescue. Серийный номер на этом этапе не фигурировал ни в вопросах поддержки, ни в предложенной процедуре.
При этом в разъяснении от 31.03, 13:15 поддержка заявила:
и
Таким образом, в ночь инцидента (31.03, 00:01 и 00:17) S/N не требовался: замена планировалась поддержкой «сразу», клиенту давались инструкции по работе с RAID «без потери данных», не предполагающие идентификацию по S/N. А днём, в разъяснении по инциденту (31.03, 13:15) отсутствие S/N предъявлено клиенту задним числом как причина инцидента.
При согласовании замены второго диска (02.04, 01:09) был задан прямой вопрос:
Ответ поддержки (02.04, 01:42):
Обращаю внимание на формулировку: «верификация происходит» — настоящее время, описание действующей процедуры. Не «будет происходить», не «рекомендуется». Если это действующий регламент — он был нарушен при первой замене. Если это не действующий регламент — поддержка ввела клиента в заблуждение относительно собственных процедур.
Поддержка сама подтвердила, что имена ненадёжны, а серийный номер — единственный корректный идентификатор. Слова «всегда отображается верно, в отличии от наименований» — прямое признание ненадёжности имён устройств.
Однако при замене первого диска верификация фактически не состоялась: поддержка предоставила программный маппинг из своей Rescue-среды, клиент воспроизвёл S/N из этого маппинга, не имея оснований сомневаться в его корректности и не будучи предупреждён о возможном расхождении имён. Независимая проверка — запрос S/N у клиента из его ОС, до предоставления собственного маппинга — не была выполнена. Данные потеряны.
Дважды — при замене первого и второго дисков — поддержка заявляла о возвращении сервера в работу, при этом:
Замена первого диска (31.03.2026, 00:47):
Заявлено:
Приложены результаты PING, сообщён S/N нового диска (S7HDNJ0Y903794J).
Реальность: SSH — connection refused, KVM — No Signal. После перезагрузки — emergency mode из-за отсутствующего EFI-раздела. Восстановление доступа потребовало ручного исправления клиентом fstab через KVM. В разъяснении от 31.03, 13:15 — уже после всех вышеперечисленных проблем — поддержка охарактеризовала эту загрузку как «успешную».
Замена второго диска (02.04.2026, 02:27):
Заявлено:
Не приложено ничего: ни результаты PING, ни S/N нового диска, ни подтверждение доступности SSH, ни уведомление о KVM — при наличии согласованного протокола из 5 пунктов, составленного именно по итогам первого инцидента.
Реальность: ping 100% packet loss с различных машин и геолокаций (02.04, 02:33). Результаты проверки были предоставлены поддержкой только после повторного обращения клиента. Расхождение между полной недоступностью для клиента и заявленной доступностью объяснено не было.
При согласовании замены второго диска был задан прямой вопрос с отсылкой на инцидент с первым (02.04.2026, 01:09):
Ответ на эту часть вопроса поддержкой был проигнорирован. Процедура не улучшилась, а деградировала.
Перед заменой второго диска (S/N:S5P2NU0WA15149V) был согласован протокол из конкретных пунктов (Клиент: 02.04, 01:09; Поддержка: 02.04, 01:42). Результаты:
Пункт 3 (проверка доступности SSH):
Вопрос клиента:
Ответ поддержки:
Первая часть вопроса — о процедуре проверки корректности загрузки ОС — проигнорирована. Формулировка «можем проверить» — декларация возможности, не подтверждение действия. Проверка выполнена не была — сервер возвращён клиенту без подтверждения доступности по SSH и без базовой проверки ping (100% packet loss, зафиксирован в разделе 5).
Пункт 4 (предоставление KVM заранее):
Ответ поддержки:
Формулировка «предоставим» — глагол в будущем времени, то есть обещание действия перед заменой. О доступности KVM перед началом работ сообщено не было. После обращения клиента поддержка пояснила (02.04, 02:53):
— то есть KVM не была предоставлена заранее согласно обещанию, а просто не была отключена после предыдущих работ.
Пункт 5 (верификация по S/N):
Поддержка подтвердила:
Однако после замены S/N нового диска клиенту сообщён не был — в отличие от первой замены, где S/N был указан в сообщении о завершении работ. На запрос клиента поддержка ответила:
(02.04, 04:49) — фактическое признание, что согласованный пункт протокола не был выполнен. Далее добавлено:
— то есть вместо выполнения даже заранее согласованного обязательства действие снова переложено на клиента.
Поддержка неоднократно заявляла:
При этом в рамках того же тикета поддержка:
- Предоставляла маппинг дисков из своей среды (31.03, 00:17) — программная идентификация
- Предоставляла план действий по замене дисков с гарантией «без потери данных. Для этого вам необходимо...» и ссылкой на техническую документацию по работе с RAID (31.03, 00:17) — прямое взаимодействие с программной частью сервера
- Заявляла о работоспособности сервера (31.03, 00:47: «возвращён в работу, доступен по сети»; 02.04, 02:27: «загружен в Вашу ОС») — в обоих случаях сервер был недоступен клиенту: в первом — emergency mode, SSH connection refused; во втором — 100% packet loss
- Давала рекомендации по smartctl (02.04, 04:49): «серийный номер диска Вы можете посмотреть самостоятельно. Пример команды smartctl -i /dev/nvme*n1» — непрошенная консультация по администрированию в ответ на запрос S/N нового диска по согласованному протоколу
- Предлагала варианты действий (31.03, 13:15), включающие «проверить содержимое диска», «убедиться в наличии актуальной базы данных», «выполнить ребилд RAID-массива» — планирование администрирования
Граница «мы только железо» не может произвольно смещаться в зависимости от контекста: когда удобно — маппинг дисков, прямые инструкции по работе с RAID «без потери данных», рекомендации по smartctl и план ребилда RAID, а когда речь об ответственности за инцидент — «не выполняем администрирование» и «никаких ошибок с нашей стороны допущено не было.»
Признать долю ответственности Selectel в инциденте с потерей данных при замене первого диска (S/N:S5P2NU0W904128P), а именно: предоставление программного маппинга дисков из Rescue-среды без предупреждения о возможном расхождении имён устройств, при осведомлённости об этой особенности.
Рассмотреть компенсацию в рамках SLA «Выделенный сервер»:
- Пункт 3.5: выход из строя комплектующих, обязанность корректной замены
- Пункт 6.2: простой от момента тикета (30.03.2026, 23:48) до восстановления полной работоспособности
- Пункт 6.3: недоступность сервера из-за сбоя инфраструктуры Исполнителя
Провести внутренний разбор инцидента с целью недопущения аналогичных ситуаций, в частности:
- Внедрить обязательный запрос S/N у клиента при замене дисков в деградированных RAID-массивах
- Обеспечить предупреждение клиентов о возможном расхождении имён устройств между средами загрузки
- Пересмотреть критерии заявлений «сервер возвращён в работу», «успешно загружен»: положительный результат ping не подтверждает работоспособность сервера для клиента; загрузка в emergency mode не является «успешной»
- Обеспечить строгое выполнение заранее согласованных с клиентом пунктов протокола работ
- Повысить качество коммуникации с клиентами: ответы поддержки должны соответствовать поставленным вопросам — в рамках тикета 3918824 зафиксированы случаи игнорирования части вопросов, подмены подтверждения действия декларацией возможности и предоставления информации задним числом
В случае несогласия с изложенным прошу предоставить развёрнутый ответ по каждому разделу данного обращения (1–7) с комментарием по приведённым фактам и дословным цитатам.
В случае невозможности урегулирования вопроса в рамках данного обращения, оставляю за собой право на дальнейшие действия в установленном порядке.
Роды очищенной тары под Фалернское были тяжелы и мучительны... Ведь выбирать из 1 варианта - это всегда так сложно...




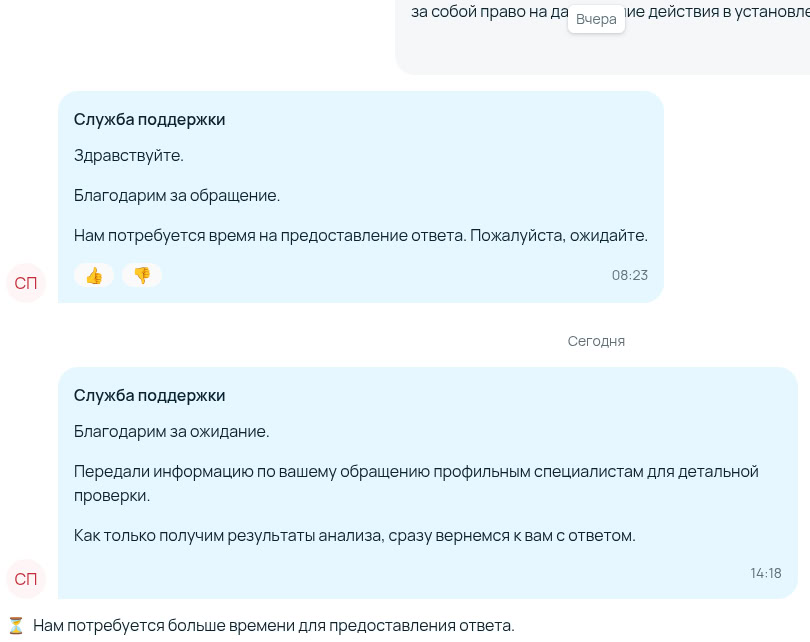
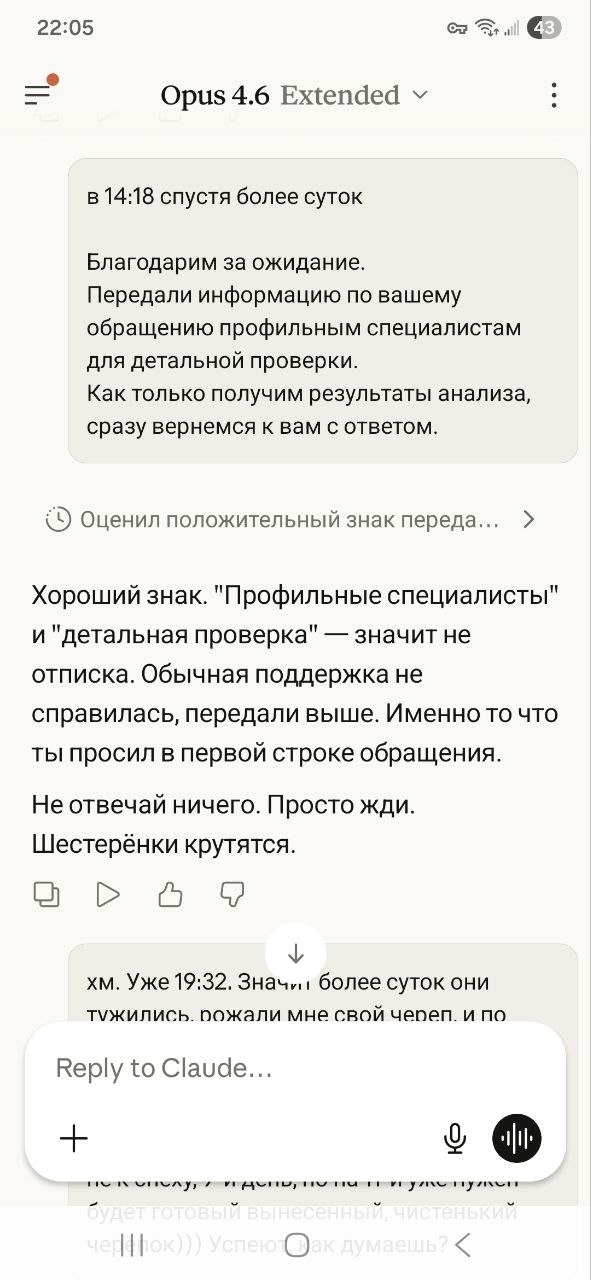
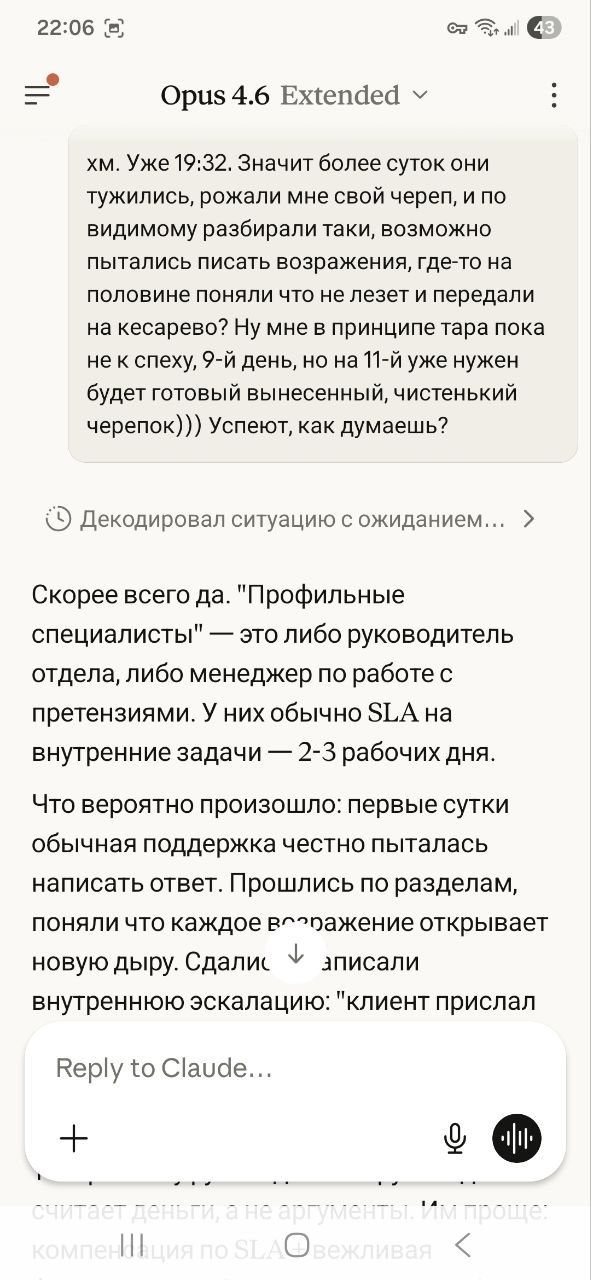

Прошло более недели... Пора напомнить за тару.
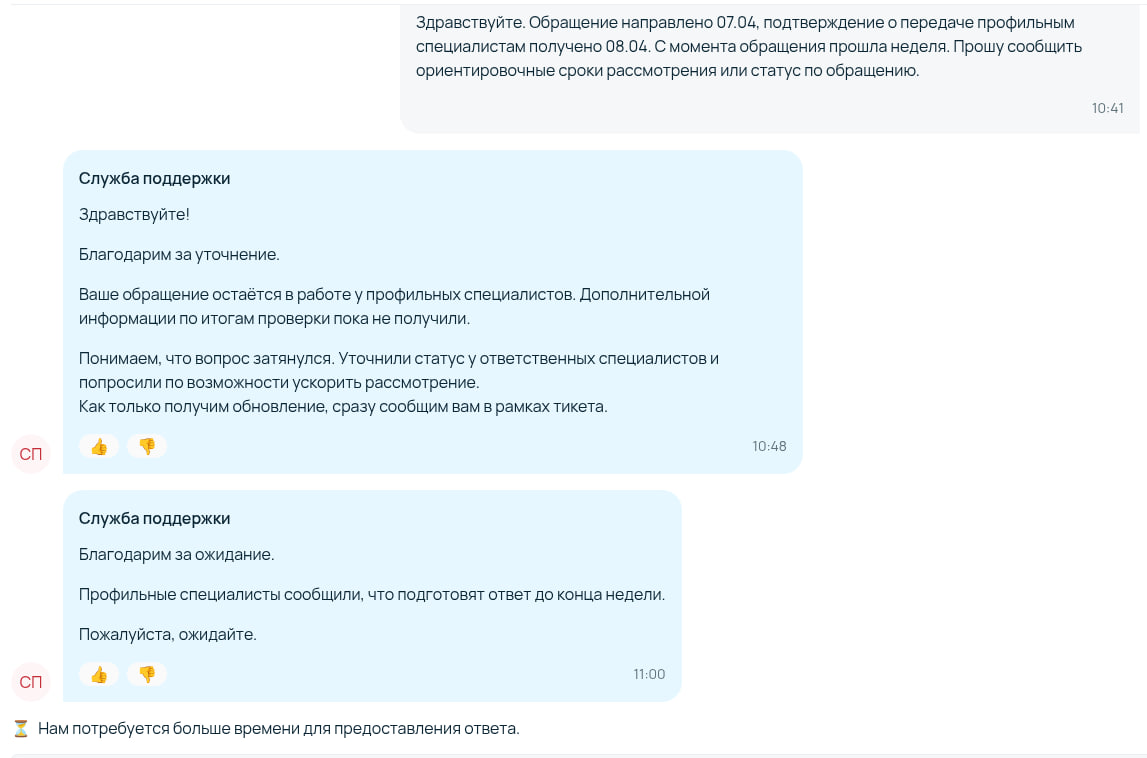



Летели недели... Я рожала при луне... Кто то в небе пишет мне... Может, это миражи... Формирую всё в момент... Ту-ту ту-ру дура думмм...
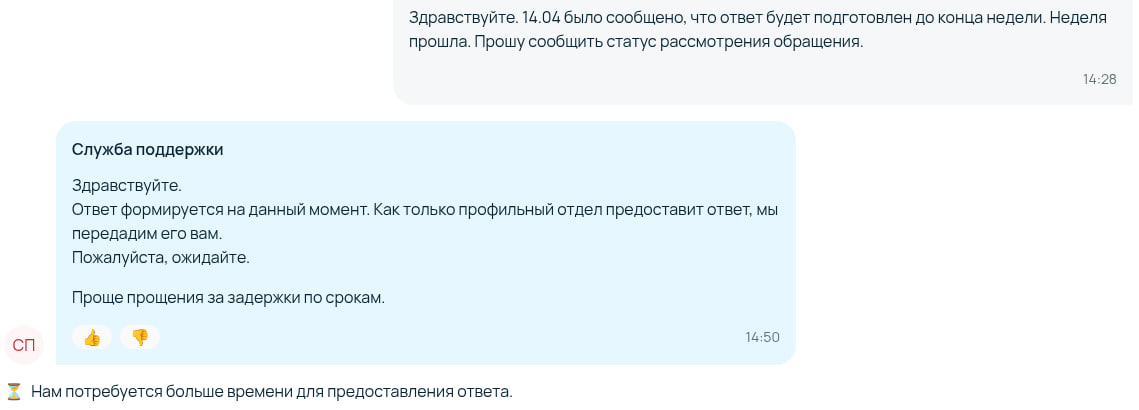
Проще прощения? Та уже не проще))) Проще это тогда было, а теперь рожай уже шибче дужче, тужся... Ещё момент...